关于本文档
欢迎来到DataStax提供的Cassandra文档。 为确保您在使用本文档时获得最佳体验,请花点时间查看使用DataStax文档的提示。
着陆页提供有关受支持平台,产品兼容性,规划和测试集群部署,推荐的生产设置,故障排除,第三方软件,更多信息的资源,管理员和开发人员主题以及早期文档的信息。
Apache Cassandra概览
Apache Cassandra™ 是一个大规模可扩展的开源NoSQL数据库。 Cassandra非常适合跨多个数据中心和云,来管理大量结构化、半结构化和非结构化数据。 Cassandra在许多商用服务器上提供持续可用性、线性可扩展性和操作简单性,而没有单点故障,以及强大的动态数据模型,旨在实现最大的灵活性和快速的响应时间。
Cassandra如何工作?
Cassandra基于可扩展的架构,意味着它能够每秒处理PB级信息和数千个并发用户/操作。
| Cassandra是一个分区的行存储数据库 | Cassandra的体系结构允许任何授权用户连接到任何数据中心的任何节点,并使用CQL语言访问数据。为了便于使用,CQL使用了与SQL相似的语法。与Cassandra互动的最基本的方式是使用CQL shell,cqlsh。使用cqlsh,您可以创建键空间和表、插入和查询表,以及更多。Cassandra的这一版本与Cassandra 2.2和后来的CQL合作。如果您喜欢图形化工具,您可以使用数据中心DevCenter。对于生产,数据中心提供了一个数字驱动程序,以便CQL语句可以从客户机传递到集群和返回。 |
|---|---|
| 自动化的数据分布 | Cassandra提供了所有参与到环(比如hash链路环)或数据库集群的节点的自动数据分布。由于数据在集群中的所有节点上都是透明的,因此,开发人员或管理员不需要进行编程,也不需要通过代码来跨集群分发数据。 |
| 内置的、可定制的复制 | Cassandra还提供了内置的和可定制的复制,它在节点上存储了冗余的数据副本。这意味着,如果集群中的任何节点宕机,该节点数据的一个或多个副本就可以在集群中的其他计算机上使用。可以将复制配置为跨一个数据中心、多个数据中心和多个云可用区域进行工作。 |
| 供应线性可伸缩性 | Cassandra 提供线性可伸缩性,这意味着通过在网络上添加新的节点可以轻松地添加容量。例如,如果2个节点每秒处理10万个事务,那么4个节点将支持200,000个事务/秒,8个节点将处理40万事务/秒: |
 |
Cassandra与关系数据库有什么不同?
Cassandra的设计是作为一个分布式数据库来进行点对点的交流。作为最佳实践,查询应该是每个表的一个。数据被规范化以使这成为可能。由于这个原因,表之间的连接的概念并不存在,尽管客户端连接可以在应用程序中使用。
什么是NoSQL?
最常见的翻译是“Not Only SQL”,这意味着使用存储方法不同于关系型数据库或SQL数据库的数据库。有许多不同类型的NoSQL数据库,因此即使是最常用的类型也没有什么用处。现在的数据库管理员必须对多语言友好,这意味着他们必须知道如何使用许多不同的RDBMS和NoSQL数据库。
什么是CQL?
Cassandra Query Language (CQL) 是Cassandra DBMS的主要接口。使用CQL类似于使用SQL(结构化查询语言)。CQL和SQL共享一个由列和行组成的表的抽象概念。与SQL的主要区别在于,Cassandra不支持连接或子查询。相反,Cassandra强调了通过CQL的特性,比如在模式层次上指定的集合和集群。
CQL是与Cassandra互动的推荐方式。性能和简单的阅读和使用CQL是现代Cassandra对旧Cassandra api的优势。
如何与Cassandra交互?
与Cassandra互动的最基本的方式是使用CQL shell,cqlsh。使用cqlsh,您可以创建键空间和表、插入和查询表,以及更多。如果您喜欢图形化工具,您可以使用DevCenter。对于生产,数据中心提供了多种编程语言的驱动程序,因此CQL语句可以从客户端传递到集群和返回。
如何把数据迁移到Cassnadra或者从Cassandra迁移数据?
使用CQL插入命令、CQL复制命令和CSV文件插入数据,或者使用sstableloader。但实际上,您需要考虑客户机应用程序如何查询这些表,并首先进行数据建模。关系和NoSQL之间的范式转换意味着,从RDBMS数据库到Cassandra的数据直接转移将注定失败。
Cassandra还有什么其他的工具吗?
Cassandra自动安装了节点工具,这是Cassandra的一个有用的命令行管理工具。在默认情况下,还安装了一个负载压力和基本基准测试的工具—cassandra-stress。
需要什么类型的硬件/云环境来运行Cassandra?
Cassandra的设计是在普通的商用硬件上运行。在云计算中,Cassandra适应了大多数的公共产品。
Apache Cassandra 3.0 新特性
Cassandra 3.0 新特性
| 存储引擎重构 | 存储引擎已经被重构了。 |
|---|---|
| 物化视图 | 物化视图处理了自动化的服务器端变性,在基础和视图数据之间保持一致。 |
| 操作的改进 | |
| 将MAX_WINDOW_SIZE_SECONDS添加到DTCS压缩管理 | 允许DTCS压缩治理基于最大窗口大小而不是SSTable年龄。 |
| 基于文件的提示存储和改进的重播 | 提示现在存储在文件中,并且重播得到改进。 |
| 垃圾收集器切换到 G1 | Default garbage collector is changed from Concurrent-Mark-Sweep (CMS) to G1. G1 performance is better for nodes with heap size of 4GB or greater. |
| 更改了CREATE TABLE压缩选项的语法 | Made the compression options more consistent for CREATE TABLE. |
| 添加nodetool命令强制重复阻止批处理日志 | BatchlogManager can force batchlog replay using nodetool. |
| 基于SSL的Nodetool | Nodetool can connect using SSL like cqlsh. |
| 用于提示的nodetool工具选项 | Nodetool options disablehintsfordc and enablehintsfordcadded. to selectively disable or enable hinted handoffs for a datacenter. |
| nodetool stop | Nodetool option added to stop compactions. |
| 其他值得注意的变化 | |
| 需要Java 8 | Java 8 is now required. |
| nodetool cfstats和nodetool cfhistograms重命名 | Renamed nodetool cfstats to nodetool tablestats. Renamed nodetool cfhistograms to nodetool tablehistograms. |
| 抛除Native protocol v1 and v2 | Native protocol v1 and v2 are dropped in Cassandra 3.0. |
| DataStax AMI does not install Cassandra 3.0 or 3.x | 您可以在Amazon EC2上安装Cassandra 2.1和更早版本,使用DataSet AMI(Amazon Machine Image),如Cassandra 2.1的AMI文档中所述。要在Amazon EC2上安装Cassandra 3.0及更高版本,请在您的平台上使用受信任的AMI 该平台的安装方法。 |
理解架构
架构简介
Cassandra旨在处理多个节点之间的大数据工作负载,无单点故障。
它的架构是基于这样的前提,即系统和硬件故障允许而且确实会发生。 Cassandra通过在同簇节点之间采用点对点分布式系统来解决故障问题,数据分布在群集中的所有节点之间。每个节点通过使用点对点Gossip通信协议频繁地跨群集交换关于自身和其他节点的状态信息。每个节点上顺序写入的commit log捕获写入操作以确保数据的持久性。然后将数据编入索引并写入内存结构,称为memtable,类似于回写缓存。每次内存结构都已满时,数据将写入SSTables数据文件中的磁盘。所有写入在整个集群中自动分区和复制。 Cassandra会使用一个名为compaction的过程定期整合SSTables,丢弃哪些已经被标记为遗弃的数据删除。为了确保集群中的所有数据保持一致,采用了各种修复机制。
Cassandra是一个分区行存储数据库,其中,行被组织成具有所需主键的表。 Cassandra的架构允许任何授权用户连接到任何数据中心的任何节点,并使用CQL语言访问数据。 为了易于使用,CQL使用与SQL类似的语法,并与表数据一起使用。 开发人员可以通过cqlsh,DevCenter访问CQL,并通过驱动程序访问应用程序语言。 通常,群集对于由许多不同的表组成的应用程序具有一个密钥空间。
客户端读或写请求可以发送到集群中的任何节点。 当客户端连接到具有请求的节点时,该节点用作该特定客户机操作的协调器。 协调器充当客户端应用程序和拥有正在请求的数据的节点之间的代理。 协调器根据集群的配置方式确定环中的哪些节点应该获取请求。
键结构
节点
存储数据的地方,这是Cassandra的基本基础设施。
数据中心
一组相关节点。数据中心可以是一个物理数据中心或虚拟数据中心。不同的工作负载应该使用单独的数据中心,无论是物理的还是虚拟的。复制是由数据中心设置的。使用单独的数据中心可以防止Cassandra的事务受到其他工作负载的影响,并将请求保持在较低的等待时间。根据复制因素,可以将数据写入多个数据中心。数据中心永远不能跨越物理位置。
集群
一个集群包含一个或多个数据中心。它可以跨越物理位置。
commit log
所有数据都首先写入提交日志,以保证持久性。在所有的数据都被刷新到s马厩后,它可以被归档、删除或回收。
SSTable
一个排序的字符串表(SSTable)是一个不可变的数据文件,Cassandra定期地写备忘录。SSTables只附加并存储在磁盘上,并为每一个Cassandra表维护。
CQL Table
由表行获取的有序列的集合。一个表由列组成,并有一个主键。
配置Cassandra的关键组件
- Gossip 一个点对点通信协议,用于发现和共享关于Cassandra集群中其他节点的位置和状态信息。当节点重新启动时,每个节点都将在本地持久保存流言信息。
- Partitioner 分区程序确定哪个节点将接收到一个数据的第一个副本,以及如何在集群中的其他节点上分发其他副本。每一行数据由主键惟一标识,这可能与它的分区键相同,但也可能包括其他集群列。分区程序是一个哈希函数,它从一行的主键派生一个令牌。分区程序使用令牌值来确定集群中的哪个节点接收该行的副本。
Murmur3Partitioner是新Cassandra集群的默认分区策略,在几乎所有的情况下,新的集群都是正确的选择。您必须设置分区,并为每个节点分配一个num_token值。您分配的令牌的数量取决于系统的硬件功能。如果不使用虚拟节点(vnode),则使用initial_token设置。 - Replication factor 跨集群的副本总数。一个复制因子1表示一个节点上的每一行只有一个副本。复制因子2表示每一行的两个副本,每个副本在一个不同的节点上。所有的副本都同等重要,没有主或主副本。您可以为每个数据中心定义复制因子。通常,您应该将复制策略设置为大于1,但不超过集群中的节点数量。
- Replica placement strategy Cassandra在多个节点上存储数据(副本),以确保可靠性和容错。复制策略决定将哪些节点放置在该节点上。数据的第一个副本只是第一个副本;它在任何意义上都不是惟一的。对于大多数部署来说, NetworkTopologyStrategy是非常推荐的,因为在未来的扩展需要时,扩展到多个数据中心要容易得多。在创建一个keyspace时,您必须定义副本放置策略和您想要的副本数量。
- Snitch Snitch将一组机器定义为数据中心和机架(拓扑),复制策略用于放置副本。您必须在创建集群时配置一个Snitch。所有的snitches都使用动态的snitch层,它可以监控性能,并选择最佳的读取副本。默认情况下启用它,并建议在大多数部署中使用它。为cassandra中的每个节点配置动态的snitch阈值。yaml配置文件。默认的SimpleSnitch不识别数据中心或机架信息。将它用于单数据中心部署或公共云中的单一区域。生产的GossipingPropertyFileSnitch推荐。它定义了一个节点的数据中心和机架,并使用流言传播这些信息到其他节点。
- The cassandra.yaml configuration file 用于设置集群的初始化属性、用于表的缓存参数、调优和资源利用率、超时设置、客户端连接、备份和安全性的主要配置文件。默认情况下,一个节点被配置为存储它管理的数据,存储在该目录中的一个目录中。
yaml文件。在生产集群部署中,您可以将提交日志目录从datafile-directory更改为不同的磁盘驱动器。 - System keyspace table properties 您可以通过编程或使用客户端应用程序,例如CQL,在每个键空间或每个表的基础上设置存储配置属性。
内部节点通信(gossip)
Gossip是一种点对点通信协议,其中节点周期性地交换关于他们自己和关于他们知道的其他节点的状态信息。 Gossip进程每秒运行一次,并与群集中最多三个其他节点交换状态消息。 节点交换有关自己和有关其他节点的关联节点的信息,所以所有节点都快速了解集群中的所有其他节点。Gossip消息具有与之相关联的版本,使得在 gossip交换期间,较旧的信息将被特定节点的最新状态覆盖。
为了防止gossip通信中的问题,请为群集中的所有节点使用相同的种子节点列表。 这是节点第一次启动时最关键的。 默认情况下,一个节点会记住它在随后的重新启动之间闲置的其他节点。 除了为加入群集的新节点引导gossip进程之外,种子节点的名称除外。 种子节点不是单点故障,在集群操作之外,除了节点的引导之外,它们也不具有任何其他特殊用途。
注意:在多个数据中心集群中,包括种子列表中每个数据中心(复制组)的至少一个节点。 建议为每个数据中心指定多个单个种子节点进行容错。 否则,gossip必须在引导节点时与其他数据中心进行通信。由于增加了维护和减少了gossip性能,因此不推荐使用每个节点的种子节点。 gossip优化并不重要,但建议使用小型种子列表(每个数据中心约三个节点)。
故障检测和恢复
故障检测是一种用于从gossip状态和历史记录中,判断系统中的另一个节点关闭或已经恢复的方法。 Cassandra使用此信息避免将客户端请求尽可能地路由到不可达节点。 (Cassandra也可以通过dynamic snitch避免路由请求到活着的节点,但性能不佳。)
Gossip负责处理从其他节点直接跟踪状态(节点直接与其通话)和间接(节点在二手,三手等上进行通信)跟踪状态。 Cassandra使用权责发生制检查机制来计算一个考虑到网络性能,工作负载和历史条件的每个节点的阈值,而不是使用固定的阈值来标记故障节点。在gossip交流期间,每个节点都保持了来自集群中其他节点的gossip消息到达时间的滑动窗口。配置phi_convict_threshold属性调整故障检测器的灵敏度。较低的值增加了无响应节点被标记为关闭的可能性,而较高的值会降低导致节点故障的瞬态故障的可能性。在大多数情况下使用默认值,但是对于Amazon EC2(由于频繁发生的网络拥塞)而将其增加到10或12。在不稳定的网络环境(如EC2有时),将值提高到10或12有助于防止虚假故障。不推荐值高于12,低于5的值。
节点故障可能是由各种原因造成的,比如硬件故障和网络中断。节点中断通常是短暂的,但可以持续很长一段时间。因为节点中断很少表示永久离开集群,所以它不会自动导致从环上删除节点。其他节点将定期尝试重新建立与失败节点的联系,以确定它们是否恢复了。为了永久更改集群中的节点成员,管理员必须使用nodetool实用程序显式地添加或删除一个Cassandra集群中的节点。
当一个节点在停机后重新上线,它可能会错过它所维护的副本数据的写入。Repair mechanisms的存在是为了恢复丢失的数据,比如提示的手动修复和nodetool repair的手工修复。中断的长度将决定使用哪个修复机制来使数据保持一致。
数据分发与复制
在Cassandra内部,数据分发和复制都在一起。数据由表组织,由主键标识,该键确定数据存储在哪个节点上。副本是行的副本。当第一次写入数据时,它也被称为副本。
影响复制的因素包括:
- Virtual nodes: 将数据所有权分配给物理机器.
- Partitioner: 在集群中给数据分区.
- Replication strategy: 确定每行数据的副本.
- Snitch: 定义复制策略用于放置副本的拓扑信息.
Consistent hashing 一致性哈希
一致性hash允许跨集群的数据分布,以便添加或删除节点时,重组能最小化。一致性hash分区数据基于分区键。(有关分区键和主键的说明,请参阅Cassandra 2.2及更高版本的CQL中的数据建模示例。)
例如, 有以下数据:
| name | age | car | gender |
|---|---|---|---|
| jim | 36 | camaro | M |
| carol | 37 | bmw | F |
| johnny | 12 | M | |
| suzy | 10 | F |
Cassandra为每个分区键分配一个hash值:
| Partition key | Murmur3 hash value |
|---|---|
| jim | -2245462676723223822 |
| carol | 7723358927203680754 |
| johnny | -6723372854036780875 |
| suzy | 1168604627387940318 |
集群中的每个节点都使用hash值来管理一系列数据。
一个四个节点的集群中的hash值。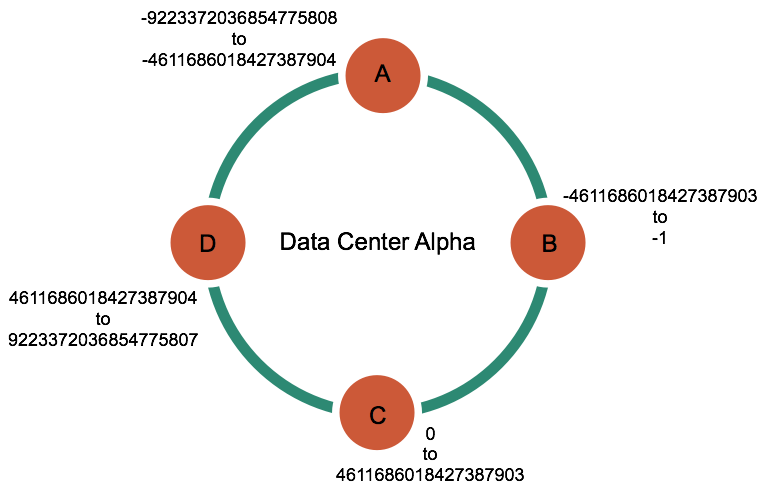
Cassandra根据分区键的值和节点管理的范围将数据放在每个节点上。 例如,在四节点集群中,本示例中的数据分布如下:
| Node | Start range | End range | Partition key | Hash value |
|---|---|---|---|---|
| A | -9223372036854775808 | -4611686018427387904 | johnny | -6723372854036780875 |
| B | -4611686018427387903 | -1 | jim | -2245462676723223822 |
| C | 0 | 4611686018427387903 | suzy | 1168604627387940318 |
| D | 4611686018427387904 | 9223372036854775807 | carol | 7723358927203680754 |
Virtual nodes(虚拟节点)
虚拟节点,一般简称为Vnodes,以更细粒度的方式在节点之间分配数据,而不是使用计算的token可以轻松实现的。 Vnodes简化了Cassandra中的许多任务:
- Tokens将自动计算并分配给每个节点。
- 添加或删除节点时,会自动实现重新平衡群集。 当节点加入集群时,它承担来自集群中其他节点的数据的偶数部分的责任。 如果一个节点出现故障,则负载在集群中的其他节点之间均匀分布。
- 重建宕机节点会更快,因为它本身就已经包含了集群中其他节点的信息。
- 分配给集群中的每个机器的vnode的比例可以调节,因此可以在构建群集时使用更小和更大的计算机。
更多信息,请参阅Cassandra 1.2中的虚拟节点。 要将现有集群转换为vnodes,请参阅启用现有生产集群上的虚拟节点。
如何通过集群分布数据(使用虚拟节点)
在Cassandra 1.2之前,您必须为群集中的每个节点计算并分配单个token。 每个token根据其hash值确定节点在环中的位置及其部分数据。在Cassandra 1.2及更高版本中,每个节点都允许许多token。 新的范例称为虚拟节点(Vnodes)。 Vnodes允许每个节点拥有分布在整个集群中的大量小分区范围。 Vnodes还使用一致hash来分发数据,但使用它们不需要生成和分配token。
虚拟化 vs 单token 架构
上半部分图:显示没有vnodes的群集。 在这个范例中,每个节点都被分配一个代表环中位置的token。 每个节点存储通过将分区密钥映射到从先前节点到其分配值的范围内的令牌值所确定的数据。 每个节点还包含集群中其他节点的每一行的副本。 例如,如果复制因子为3,范围E复制到节点5,6和1.请注意,节点在环空间中只拥有一个连续的分区范围。
下半部分图:显示带有vnodes的环。 在集群中,虚拟节点被随机选择并且不连续。 行的放置由属于每个节点的许多较小分区范围内的分区密钥的hash确定。
数据复制
Cassandra将副本存储在多个节点上,以确保可靠性和容错能力。 复制策略确定放置副本的节点。 集群中的副本总数称为复制因子。 复制因子为1表示集群中每行只有一个副本。 如果包含行的节点关闭,则无法检索该行。 复制因子2表示每行的两个副本,其中每个副本位于不同的节点上。 所有副本同样重要; 没有主副本。 作为一般规则,复制因子不应超过集群中的节点数。 但是,您可以增加复制因子,然后稍后添加所需数量的节点。
以下是两种可用的复制策略:
SimpleStrategy: 仅用于单个数据中心和一个机架, 如果您打算使用多个数据中心,请使用NetworkTopologyStrategy。NetworkTopologyStrategy: 强烈推荐用于大多数部署,因为在将来的扩展需要的时候,它更容易扩展到多个数据中心。
SimpleStrategy
仅用于单个数据中心和一个机架。 SimpleStrategy将第一个副本放置在由分区器确定的节点上。 额外的副本被放置在环的顺时针的下一个节点上,而不考虑拓扑(机架或数据中心位置)。
NetworkTopologyStrategy
您有(或计划拥有)多个数据中心部署的群集时,请使用NetworkTopologyStrategy。此策略指定每个数据中心中需要多少个副本.NetworkTopologyStrategy将副本放在同一个数据中心中,方法是顺时针旋转环直到到达另一个机架中的第一个节点。 NetworkTopologyStrategy尝试将副本放在不同的机架上,因为同一机架(或类似的物理分组)中的节点由于电源,冷却或网络问题而经常同时发生故障。当决定在每个数据中心配置多少份副本时,考虑因素是(1)能够本地满足读取,而不会导致跨数据中心延迟,以及(2)故障情形。配置多个数据中心集群的两种最常见方法是:每个数据中心中的两个副本:此配置可以容许每个复制组中的单个节点发生故障,并且仍然允许本地读取在一个一致性级别。每个数据中心的三个副本:此配置每个复制组中的一个节点在
LOCAL_QUORUM的强一致性级别或使用一致性级别ONE的每个数据中心的多个节点故障时可能会发生故障。不对称复制分组也是可能的。例如,您可以在一个数据中心中拥有三个副本,以提供实时应用程序请求,并在其他地方使用单个副本来运行分析。
每个密钥空间定义复制策略,并在密钥空间创建期间设置复制策略。 要设置密钥空间,请参阅创建密钥空间。
有关复制策略选项的更多信息,请参阅更改密钥空间复制策略。
分区器
分区器确定数据如何在集群中的节点(包括副本)上分布。 基本上,分区器是用于从其分区键(通常通过散列)导出表示行的令牌的函数。 然后通过令牌的值将每行数据分布在集群中。
Murmur3Partitioner和RandomPartitioner都使用令牌来帮助将相等的数据分配给每个节点,并将数据从所有表格均匀地分布在整个环或其他分组(例如键空间)中。 即使表格使用不同的分区键(例如用户名或最小化)也是如此。 此外,对集群的读取和写入请求也是均匀分布的,并且简化了负载平衡,因为散列范围的每个部分平均接收到相等数量的行。 有关更多详细信息,请参阅一致散列。
两个分区器之间的主要区别是每个分区器如何生成token hash。 RandomPartitioner使用比Murmur3Partitioner更长的生成加密哈希值。 Cassandra并不需要加密散列,所以使用Murmur3Partitioner可以提高3-5倍的性能。
Cassandra提供了可以在cassandra.yaml file文件中设置的以下分区器。
Murmur3Partitioner(默认): 基于MurmurHash哈希值,统一分布整个群集中的数据。RandomPartitioner: 根据MD5哈希值,统一分布整个群集的数据。ByteOrderedPartitioner: 通过关键字节保持数据的有序分布。
Murmur3Partitioner是Cassandra 1.2及更高版本的新集群的默认分区策略,几乎在所有情况下都是新集群的正确选择。 但是,分区器不兼容,并且用一个分区器分区的数据不能轻易地转换为其他分区器。
Note:如果使用虚拟节点(vnodes),则不需要计算令牌。 如果不使用vnodes,则必须计算要分配给cassandra.yaml 文件中的 initial_token 参数的令牌。 请参阅生成令牌,并使用您正在使用的分区器类型的方法。
Murmur3Partitioner
Murmur3Partitioner是默认分区器。 Murmur3Partitioner提供比RandomPartitioner更快的hash和改进的性能。 Murmur3Partitioner可以与vnodes一起使用。 但是,如果不使用vnodes,则必须按照生成token中的描述计算token。
将Murmur3Partitioner用于新集群; 您不能更改使用其他分区器的现有群集中的分区。 Murmur3Partitioner使用MurmurHash功能。 此散列函数创建分区密钥的64位哈希值。 哈希值的可能范围是 到 -1。
使用Murmur3Partitioner时,可以使用CQL查询中的令牌功能来浏览所有行。
RandomPartitioner
RandomPartitioner是Cassandra 1.2之前的默认分区器。 它被包括用于向后兼容。 RandomPartitioner可以与虚拟节点(vnodes)一起使用。 但是,如果不使用vnodes,则必须按照生成令牌中所述计算令牌.RandomPartitioner使用行密钥的MD5哈希值在节点间均匀分布数据。 哈希值的可能范围为0到 -1。
使用RandomPartitioner时,可以使用CQL查询中的令牌函数来浏览所有行。
ByteOrderedPartitioner
Cassandra提供了ByteOrderedPartitioner进行有序分区。 它被包括用于向后兼容。 该分区器按照字节顺序排列行。 您可以通过查看分区密钥数据的实际值并使用密钥中的主要字符的十六进制表示来计算token。 例如,如果要按字母顺序分区行,则可以使用其十六进制表示41来分配A token。
使用有序的分区器可以通过主键进行有序扫描。 这意味着您可以扫描行,就像您将光标移动到传统索引一样。 例如,如果您的应用程序具有用户名作为分区键,则可以扫描名称位于Jake和Joe之间的用户的行。 这种类型的查询不可能使用随机分区的分区键,因为密钥按照它们的MD5哈希(不是顺序)的顺序存储。
尽管有能力对行进行范围扫描听起来像有序分区器的理想特征,但是有一些方法可以使用表索引来实现相同的功能。
不推荐使用有序的分区器,原因如下:
负载均衡困难
负载平衡集群需要更多的管理开销。 有序分区器要求管理员根据分区密钥分发的估计值手动计算分区范围。 在实践中,这需要主动移动节点token,以适应数据一旦被加载的实际分布。
顺序写入容易引起过热节点
如果您的应用程序一次写入或更新顺序的行块,则写入不会分布在集群中; 他们都去一个节点。 对于处理时间戳数据的应用程序,这通常是一个问题。
多表的负载平衡不均衡
如果您的应用程序有多个表,那么这些表有可能具有不同的行键和不同的数据分布。 对于一个表平衡的有序分区器可能会导致同一集群中另一个表的热点和不均匀分布。
Snitches
Snitch决定哪个数据中心和架子节点属于哪个。他们将网络拓扑告知Cassandra,以便有效地路由请求,并允许Cassandra通过将机器分组到数据中心和机架来分发副本。具体来说,复制策略将副本基于新snitch提供的信息。所有节点必须返回到相同的机架和数据中心。Cassandra最好不要在同一个机架上有多个副本(这并不一定是一个物理位置)。
注意:如果您更改snitches,您可能需要执行其他步骤,因为snitch会影响放置副本的位置。 请参阅切换线程。
动态报告
默认情况下,所有的snitches都使用一个动态的snitch层来监视读取延迟,并且在可能的情况下,将请求路由到执行较差的节点。动态的snitch是默认启用的,建议在大多数部署中使用。有关如何工作的信息,请参见Cassandra:过去、现在和未来的动态snitch。为每个节点配置动态的snitch阈值。yaml配置文件。
有关更多信息,请参见在故障检测和恢复中列出的属性。
SimpleSnitch
SimpleSnitch(默认)只用于单数据中心部署。它不承认数据中心或机架信息,只能在公共云中的单数据中心部署或单区使用。它将策略顺序视为接近性,它可以在禁用读修复时提高缓存位置。
使用SimpleSnitch,您可以定义keyspace来使用SimpleStrategy并指定一个复制因子。
RackInferringSnitch
The RackInferringSnitch determines the proximity of nodes by rack and datacenter, which are assumed to correspond to the 3rd and 2nd octet of the node’s IP address, respectively. This snitch is best used as an example for writing a custom snitch class (unless this happens to match your deployment conventions).
RackInferringSnitch决定了通过机架和数据中心的临近节点,这些节点被假定分别对应于节点IP地址的第3和第2个数字。这个snitch最好用于编写一个定制的snitch类(除非这恰好符合您的部署约定)。

PropertyFileSnitch
这个snitch决定了由机架和数据中心决定的距离。它使用位于cassandra拓扑中的网络详细信息。属性文件。当使用这个snitch时,您可以定义您的数据中心名称来做任何您想要的。确保数据中心名称与keyspace定义中数据中心的名称相关。集群中的每个节点都应该在cassandra拓扑中描述。属性文件,这个文件在集群中的每个节点上都应该是完全相同的。
Procedure
如果您有不一致的IPs和两个物理数据中心,每一个都有两个机架,还有一个用于复制分析数据的第三个逻辑数据中心,即cassandra拓扑。属性文件可能是这样的:注意:数据中心和机架名称区分大小写。
1 | # datacenter One |